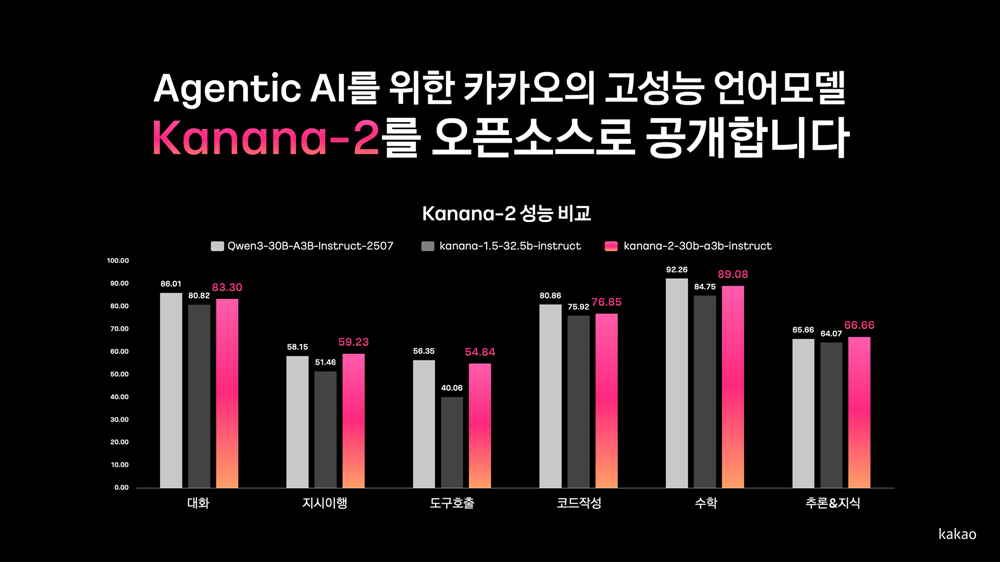
Kakao uploaded a performance comparison graph of Kanana-2, Kanana-1.5, and Qwen3 alongside the open-source release of Kanana-2. | Image provided by Kakao
Kakao announced on the 19th that it has released its self-developed next-generation language model, ‘Kanana-2,’ as open source on Hugging Face. Through this release, Kakao demonstrated its competitiveness in high-performance, high-efficiency technologies optimized for the implementation of agentic AI.
Since unveiling its proprietary AI model lineup ‘Kanana’ last year, Kakao has consistently released models as open source, ranging from lightweight versions to ‘Kanana-1.5,’ which is specialized for solving high-difficulty problems. The newly released ‘Kanana-2’ represents the latest research results, featuring significantly improved performance and efficiency, and focuses on realizing AI that understands the context of user commands and operates proactively like a “collaborative partner.”
The newly released lineup consists of three models: the Base model, the Instruct model enhanced through post-training to improve instruction-following capabilities, and, for the first time, a Thinking model specialized for reasoning. Notably, Kakao disclosed all training-stage weights (learned parameter values), enabling developers to fine-tune the models freely with their own data.
Kanana-2 shows substantial improvements in tool-calling and instruction-following capabilities, which are core to the implementation of agentic AI. Compared to the previous model (Kanana-1.5-32.5b), its multi-turn tool-calling performance has improved by more than 3x, and the model is designed to understand and execute complex, step-by-step requirements accurately. Supported languages have expanded from Korean and English to six—Korean, English, Japanese, Chinese, Thai, and Vietnamese—enhancing overall usability.
From a technical standpoint, Kakao adopted the latest architecture to maximize efficiency. Kanana-2 applies the ‘MLA (Multi-head Latent Attention)’ technique to process long inputs efficiently and incorporates an ‘MoE (Mixture of Experts)’ structure that activates only the parameters required during inference. This enables efficient handling of long contexts with fewer memory resources while reducing computational costs and improving response speed. The model also achieves significantly higher throughput, capable of handling large-scale concurrent requests at exceptional speed.
Performance benchmarks further confirmed its global competitiveness. The Instruct model achieved a level comparable to ‘Qwen3-30B-A3B,’ a recent model with a similar architecture. It was also pre-released to participants at the ‘AI Agent Competition,’ co-hosted with the Korean Institute of Information Scientists and Engineers earlier this month, where its strong applicability in real-world agent development environments was validated. The reasoning-specialized model also demonstrated performance comparable to ‘Qwen3-30B-A3B’ in thinking mode across benchmarks that require advanced reasoning, highlighting its potential as a reasoning-focused AI.
Looking ahead, Kakao plans to scale up model sizes using the same MoE structure and further enhance its advanced instruction-following capabilities. In parallel, the company will continue developing models tailored to complex AI agent scenarios and further advancing lightweight on-device models.
“High-performance and efficient language models are the foundation of innovative AI services,” said Byung-Hak Kim, Performance Lead of Kakao’s Kanana project. “Beyond focusing solely on performance, we aim to develop practical AI models that can be applied to real services and operate quickly and effectively. By continuously sharing them as open source, we hope to contribute to revitalizing the domestic and global AI research ecosystem.”